
Big Data Training
There is an enormous need for big data analysts in IT industries since information technology handles millions of data every single moment. In order to keep track of and to analyze the data, the contribution of big data analysts is highly appreciated among IT companies.
In that same vein, Hadoop is an open-source software framework which is used to store the data sporadically and to process the datasets of big data. It is done with the aid of MapReduce programming model. With a lot of commodity hardware nodes, Hadoop posits it as possible to run applications on systems.
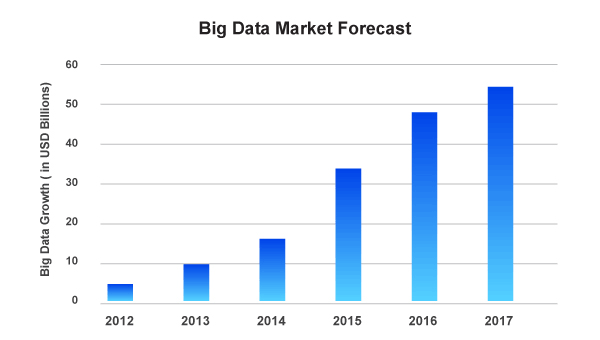
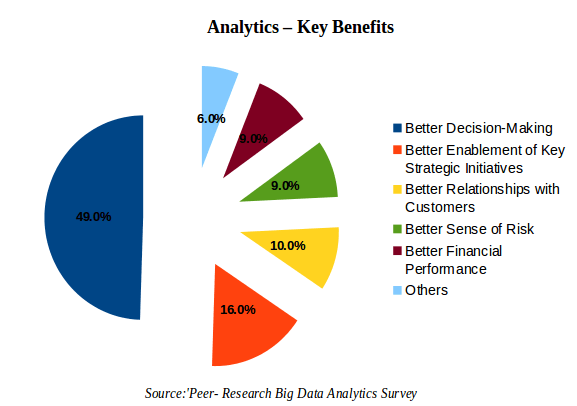
According to a survey reports, more than 60% of modern corporations are solely depending on big data analytics to raise the organization’s social media marketing abilities. And, more importantly, in another survey conducted by Peer-Research Big Data Survey, they list the benefits of big data for a big company.

Big Data Features
The big data Hadoop certification course offered by Hope Tutors is designed to give you the complete insight into the big data framework by giving you a thorough understanding of HDFS, YARN and MapReduce. We will train you to analyse the data that is collectively stored in HDFS. Using Flume for the digestion of data also is trained in our big data training course.
Processing the data with Spark is a major part of our Hadoop big data training course as you will learn different interactive algorithms and how to use Spark SQL to generate, transform and query the data forms. And during our big data training course, you are going to work out industrial level projects in the sectors of telecommunication and social media for the deeper understanding of big data.
MapReduce is the essential component of Apache Hadoop software framework and MapReduce is notable for its ability to sort out through unstructured data sets. So learning MapReduce will enrich your ability to navigate datasets that is in its primal form.
Our best Hadoop big data training course in Chennai also covers PIG and SQOOP aspects as well. With PIG, its structure is so flexible that it can be substantially parallelized. Its textual language is vital to handle very large datasets. In addition, Sqoop is used to transfer the data from Hadoop to the database servers, vice versa.
YARN – Yet Another Resource Negotiator – is a cluster management program. YARN is a wide-reaching operating system for big data applications. All of these will be covered in Hope Tutors’ big data training course. All these tools are put together and easily integrated with Hadoop and the big data will be processed faster.
We hope this video here will illustrate big data
Hope Tutors Big Data Course Features
Our Hope Tutors Big Data Training Center in Chennai is a distinguished milestone in guiding students in their career path. Situated in the main part of Velachery, Chennai, our best Hadoop Big Data Training Center is offering students the best training they could ever have. Hope Tutors leads you through a step-by-step process to learn the effective force of big data.
Not only Hope Tutors provides classroom sessions, we lead the students through the practical application of what they have just learned. It is one of the many striking features of Hope Tutors. Students are given in-depth and clear understanding of big data and are trained in a good environment.
Our trainers have adequate knowledge and are very experienced experts in big data analysis. They guide you to achieve your career goals with much efficiency.
What will you learn from our Big Data Training?
- First of all, you will understand Flume architecture and its configuration.
- The functionality of RBDMS and its workings in relation to HBase. The differences between them also will be covered.
- Understanding Spark SQL and how to create and run its frameworks.
- With Hive and Impala, you will learn how to create a new database. And learning to use Hive and Impala to partition.
Online Big Data Training
Besides our classroom training, Hope Tutors Big Data Training Institute provides online training sessions to those who want to learn the course easily from their home.

To whom the Big Data is for?
- Analytics professionals
- Data analysts
- Senior IT professionals
- Data management professionals
- Project managers
- Business intelligence professionals
So having a certified training in big data will certainly boost your career opportunities. Our Hope Tutors Big Data Training Centre in Chennai will make your dreams come true to become an assured big data analyst.

Big Data and Hadoop Course Certification
Why is certification in big data important?
- Just being graduated is not enough to equip your future in big data
- Big companies are hiring big data analysts who are extraordinarily trained with Hadoop in best institutes
- You could learn the complete skills that is necessary to be an effective big data analyst
Q&A
- How big data analysis helps businesses to multiply their revenue?
For a company to speed-up its outcome it has to analyze consumers’ preferences and choices and analyze the data to launch new products and recommendations. Thus this new approach increases the company’s revenue.
- Distinguish structured & unstructured data.
Unstructured data is something that is not established in advance that includes metadata, audio, video, FB posts and Twitter tweets which is not gathered as a whole in a database, while a structured data is well-organized like numbers and dates in order and it can be easily stored, managed and processed.
- What are the major elements of Hadoop application?
- YARN
- HDFS
- Hadoop Common
- PIG
- SQOOP
- What is HDFS in big data?
Hadoop Distributed File System is the storage component of Hadoop which serves as the data collector which stores varieties of data as blocks.
- What are the major concepts of Hadoop framework?
MapReduce and HDFS are the main concepts found in Hadoop.
FAQ
- What is the course duration for big data in Hope Tutors?
It takes 30 hours of training in big data.
- Can the course fee be paid in installment?
Of course! We accept the course fee in installment structure.
- Is online training available?
Yes, Hope Tutors provides online sessions.
- Can I attend the training on weekends?
Yes, if you cannot attend classes on weekdays, we’ve arranged weekend sessions.
- I am not sure about if I would join Hope Tutors. What to do?
To know what we are teaching you could request a free demo.
Upgrade Your Skills with Corporate Training
Corporate Training is a powerful tool to enhance and improve skills for professional growth. It offers individuals the opportunity to acquire new knowledge, develop essential competencies, and stay ahead in their careers. Through corporate training programs, participants can enhance their expertise in various areas such as leadership, communication, problem-solving, and technical skills. These programs provide a structured learning environment that enables individuals to learn from industry experts, engage in interactive workshops, and collaborate with peers. By investing in corporate training, individuals can stay updated with the latest industry trends, acquire in-demand skills, and increase their marketability. Moreover, corporate training fosters a culture of continuous learning, personal development, and professional advancement. It equips individuals with the tools and resources to adapt to changing business environments, drive innovation, and excel in their roles. Embracing corporate training is a proactive step towards success in today’s dynamic and competitive professional landscape.
Big Data Interview Questions with Answers
Course Curriculum
| Hadoop YARN Introduction | 00:00:00 | ||
| Hadoop YARN Setup | 00:00:00 | ||
| Programming in YARN framework j | 00:00:00 | ||
| Understanding big data and Hadoop | |||
| Big Data | 00:00:00 | ||
| Limitations and Solutions of existing Data Analytics Architecture | 00:00:00 | ||
| Hadoop Features | 00:00:00 | ||
| Hadoop Ecosystem | 00:00:00 | ||
| Hadoop 2.x core components | 00:00:00 | ||
| Hadoop Storage: HDFS | 00:00:00 | ||
| Hadoop Storage : Azure Data Lake Introduction | 00:00:00 | ||
| Hadoop Processing: MapReduce Framework | 00:00:00 | ||
| Hadoop Different Distributions. | 00:00:00 | ||
| Hadoop Mapreduce Framework & YARN | |||
| MapReduce Use Cases | 00:00:00 | ||
| Traditional way Vs MapReduce way | 00:00:00 | ||
| Why MapReduce | 00:00:00 | ||
| Hadoop 2.x MapReduce Architecture | 00:00:00 | ||
| Hadoop 2.x MapReduce Components | 00:00:00 | ||
| YARN MR Application Execution Flow | 00:00:00 | ||
| YARN Workflow | 00:00:00 | ||
| Anatomy of MapReduce Program | 00:00:00 | ||
| Demo on MapReduce. Input Splits | 00:00:00 | ||
| Relation between Input Splits and HDFS Blocks | 00:00:00 | ||
| MapReduce: Combiner & Partitioner | 00:00:00 | ||
| Demo on de-identifying Health Care Data set | 00:00:00 | ||
| Demo on Weather Data set. | 00:00:00 | ||
| Hadoop Architecture and HDFS | |||
| Hadoop 2.x Cluster Architecture – Federation and High Availability | 00:00:00 | ||
| A Typical Production Hadoop Cluster | 00:00:00 | ||
| Hadoop Cluster Modes | 00:00:00 | ||
| Common Hadoop Shell Commands | 00:00:00 | ||
| Hadoop 2.x Configuration Files | 00:00:00 | ||
| Single node cluster and Multi node cluster set up Hadoop Administration. | 00:00:00 | ||
| Advanced Mapreduce | |||
| Counters | 00:00:00 | ||
| Distributed Cache | 00:00:00 | ||
| Reduce Join | 00:00:00 | ||
| Custom Input Format | 00:00:00 | ||
| Sequence Input Format | 00:00:00 | ||
| Xml file Parsing using MapReduce. | 00:00:00 | ||
| Pig | |||
| About Pig | 00:00:00 | ||
| MapReduce Vs Pig | 00:00:00 | ||
| Pig Use Cases | 00:00:00 | ||
| Programming Structure in Pig | 00:00:00 | ||
| Pig Running Modes | 00:00:00 | ||
| Pig components | 00:00:00 | ||
| Pig Execution | 00:00:00 | ||
| Pig Latin Program | 00:00:00 | ||
| Data Models in Pig | 00:00:00 | ||
| Pig Data Types | 00:00:00 | ||
| Shell and Utility Commands | 00:00:00 | ||
| Pig Latin : Relational Operators | 00:00:00 | ||
| File Loaders | 00:00:00 | ||
| Group Operator | 00:00:00 | ||
| COGROUP Operator | 00:00:00 | ||
| Joins and COGROUP | 00:00:00 | ||
| Union | 00:00:00 | ||
| Diagnostic Operators | 00:00:00 | ||
| Specialized joins in Pig | 00:00:00 | ||
| Built In Functions ( Eval Function | 00:00:00 | ||
| Load and Store Functions | 00:00:00 | ||
| Math function | 00:00:00 | ||
| String Function | 00:00:00 | ||
| Date Function | 00:00:00 | ||
| Pig UDF | 00:00:00 | ||
| Piggybank | 00:00:00 | ||
| Parameter Substitution ( PIG macros and Pig Parameter substitution ) | 00:00:00 | ||
| Pig Streaming | 00:00:00 | ||
| Testing Pig scripts with Punit | 00:00:00 | ||
| Aviation use case in PIG | 00:00:00 | ||
| Pig Demo on Healthcare Data set. | 00:00:00 | ||
| Hive | |||
| Hive Background | 00:00:00 | ||
| Hive Use Case | 00:00:00 | ||
| About Hive | 00:00:00 | ||
| Hive Vs Pig | 00:00:00 | ||
| Hive Architecture and Components | 00:00:00 | ||
| Metastore in Hive | 00:00:00 | ||
| Limitations of Hive | 00:00:00 | ||
| Comparison with Traditional Database | 00:00:00 | ||
| Hive Data Types and Data Models | 00:00:00 | ||
| Partitions and Buckets | 00:00:00 | ||
| Hive Tables(Managed Tables and External Tables) | 00:00:00 | ||
| Importing Data | 00:00:00 | ||
| Querying Data | 00:00:00 | ||
| Managing Outputs | 00:00:00 | ||
| Hive Script | 00:00:00 | ||
| Hive UDF | 00:00:00 | ||
| Retail use case in Hive | 00:00:00 | ||
| Hive Demo on Healthcare Data set. | 00:00:00 | ||
| Advanced Hive and Hbase | |||
| Hive QL: Joining Tables | 00:00:00 | ||
| Dynamic Partitioning | 00:00:00 | ||
| Custom Map/Reduce Scripts | 00:00:00 | ||
| Hive Indexes and views Hive query optimizers | 00:00:00 | ||
| Hive : Thrift Server | 00:00:00 | ||
| User Defined Functions | 00:00:00 | ||
| HBase: Introduction to NoSQL Databases and HBase | 00:00:00 | ||
| HBase v/s RDBMS | 00:00:00 | ||
| HBase Components | 00:00:00 | ||
| HBase Architecture | 00:00:00 | ||
| Run Modes & Configuration | 00:00:00 | ||
| HBase Cluster Deployment. | 00:00:00 | ||
| Advanced Hbase | |||
| HBase Data Model | 00:00:00 | ||
| HBase Shell | 00:00:00 | ||
| HBase Client API | 00:00:00 | ||
| Data Loading Techniques | 00:00:00 | ||
| ZooKeeper Data Model | 00:00:00 | ||
| Zookeeper Service | 00:00:00 | ||
| Zookeeper | 00:00:00 | ||
| Demos on Bulk Loading | 00:00:00 | ||
| Getting and Inserting Data | 00:00:00 | ||
| Filters in HBase. | 00:00:00 | ||
| Getting started with Sqoop | |||
| In this module, you will be introduced to Hadoop you will get to know the Traditional database’s application. Also, you will get to know the basics of Sqoop. | 00:00:00 | ||
| Sqoop as an Import/Export tool | 00:00:00 | ||
| Sqoop Import Process | 00:00:00 | ||
| Basic Sqoop Commands | 00:00:00 | ||
| Importing Data in HDFS using Sqoop | 00:00:00 | ||
| Exporting Data from HDFS | 00:00:00 | ||
| :Import /Export Data between RDBMS and Hive/HBase | 00:00:00 | ||
| FLUME | |||
| Architecture | 00:00:00 | ||
| Flume events | 00:00:00 | ||
| Inceptors, channel ,sink processor | 00:00:00 | ||
| Twitter Data in HDFS | 00:00:00 | ||
| Telnet as source and HBase as a sink | 00:00:00 | ||
| Twitter Data in HBase | 00:00:00 | ||
| Oozie and Hadoop project | |||
| Oozie | |||
| Oozie Components | 00:00:00 | ||
| Oozie Workflow | 00:00:00 | ||
| Scheduling with Oozie | 00:00:00 | ||
| Demo on Oozie Workflow | 00:00:00 | ||
| Oozie Co-ordinator | 00:00:00 | ||
| Oozie Commands | 00:00:00 | ||
| Oozie Web Console | 00:00:00 | ||
| Oozie for MapReduce | 00:00:00 | ||
| PIG | 00:00:00 | ||
| Hive and Sqoop | 00:00:00 | ||
| Combine flow of MR | 00:00:00 | ||
| Hive in Oozie | 00:00:00 | ||
| Hadoop Project Demo | 00:00:00 | ||
| Hadoop Integration with Talend. | 00:00:00 | ||
| Understanding Apache Kafka and Kafka Cluster | |||
| Need for Kafka | 00:00:00 | ||
| Core Concepts of Kafka | 00:00:00 | ||
| Kafka Architecture | 00:00:00 | ||
| Where is Kafka Used | 00:00:00 | ||
| Processing Distributed data with Apache spark | |||
| What is Apache Spark | 00:00:00 | ||
| Spark Ecosystem | 00:00:00 | ||
| Spark Components | 00:00:00 | ||
| History of Spark and Spark Versions/Releases | 00:00:00 | ||
| Spark a Polyglot | 00:00:00 | ||
| What is Scala? | 00:00:00 | ||
| Why Scala? | 00:00:00 | ||
| SparkContext | 00:00:00 | ||
| RDD | 00:00:00 | ||
Features
FAQ
Course Reviews
Related Courses

Data Science Online Training
PRIVATE 3945Splunk Training in Chennai
PRIVATE 2135Qliksense Training in Chennai
Apply to enroll 2833



Best Hadoop Training
My trianer Mr. Adthiyan Rajendran trained me each and every concepts in a vivid manner. Good environment to get trained. Excellent placement assistance. Training based on both technical and non technical. After my course completion i can realise the standard in me. Thanks Hope tutors
I recommend Hope TUTORS
I am jasmine. I have completed my hadoop course in Hope tutors. The best practice i admire from Hope tutors is their training methods and placement assistance. We got trained in a manner to crack the hurdles we face during interviews. Thanks Hope tutors. You have changed my life better
Best Big Data Training
I am Jayalakshmi from chennai. I came to know about hope tutors through my friend. I complete my Big Data & Hadoop classroom training course here. Institute with good faculties and good infrastructure. Centrailised WIFI. Such a best place to learn.
Professional training
Stuffed trainers with good practical knowledge. Since my trainer Mr. Sathish is a working professional he gave me real time projects to train me.
Practical oriented bigdata training in chennai
I have completed my hadoop course in Hope tutors. They trained us with view to work in a big MNC. Professional oriented training.Good practical knowledge
Effiecient training
Hello, this id Divya from velachery. I attended big data training in Hope tutors, which was a awesome start up for me to learn big data further.I have a put a constraint to hope tutors that to complete my training in a week time. In a short period of requested time they covered all the topics in an effective manner (Both theoretical and practical). Am very much thankful to Mr. Sathish (big data trainer). I choosed this training center as it was in velachery, but it was really a good experience I had in a weeks time. Thanks Hope tutors.
Good faculty
Hope Tutors having very good faculty for Big Data/Hadoop. The institute is providing real-time training for software professionals at Basic, Intermediate and Advanced level in well manner. Infrastructure/ facility is good.
Best training
I?m learning big data concepts in hope tutors since last 3 months. I?m writing this review to share my experiences about the institution and faculty members. It?s a great journey where I learnt all of concepts in big data with live examples. The ambience is excellent and the trainer is well trainer and having live professional experience in big data
Great Learning
Great Learning!! Good Ambience!! I was here for Big-data, From Non-Technology Background! Trainer was able to make me understand with realtime examples which helps lot when it comes to Complex subjects!! which shows he knows the industry in and out!
Good Training
I have joined Big Data analytics course in Hope tutors and have gained experience in concepts like Hadoop, Mapreduce, Hive, Pig. The overall coaching is very good and easily understandable as the project and training are based on the real-time scenarios. I thank ppl here for the coaching and knowledge shared with me.
Excellent place to learn a new technology
Excellent place to learn a new technology from the experienced people in friendly atmosphere.
I have learned hadoop ecosystem (HDFS Architecture,Mapreduce,Hive,Pig )here,My trainer is sathish, who is teach me the entire structure of data warehouse in the real world and its uses in data analytic.
Really thanks a lot to him……
Best Institute For Big data
Best training institute for Bigdata i joined there and complete my training. Really my trainer is stuffed guy having wide knowledge in all concepts. Useful training.
Best training institute for professional
I am having 5 yrs of experience in java. Joined Hope tutors for Bigdata training. Really the way of concepts explanation is good. I suggest some of friends to join there.Best institute for professionals
Good training experience
thanks Hope tutors and trainer for my training. Really good experience. My wishes for your future success